“Metadata specialists need to know their users, their collections and resources, and the information organisation systems they are working with (sic). They also need to develop an eye for detail, a very clear, succinct form of expression and a systematic and thorough approach. Faced with choices about what and how to describe, they need to apply principles as well as standards” (Hider, 2018, p.103).
Quality metadata: effective, functional, comprehensive, accurate and consistent
If metadata is of the highest quality, that is: effective, functional, comprehensive, accurate and consistent, then users, even with their complex information seeking needs (which they themselves may not even know) are commonly more satisfied (Hider, 2018, p.93-94). The best way to ensure the highest quality, including effectiveness, functionality, comprehension, accuracy, and consistency is through metadata standards and / or use of standards in terms of setting’s community of practice (Hider, 2018, p.123).
Functionality:
Knowing the user information needs (rather than assuming their needs, basing cataloguing on the cataloguer ideas or opinions of librarians) leads to better database quality (Hider, p. 94);
Standardised indexing aids in the Functional Requirements for Bibliographic Records (FRBR) finding (Hider, 2018, p.94);
Standardised displays aid FRBR selecting (Hider, 2018, p. 94).
Comprehensiveness:
Comprehensive metadata requires a choice: more resources with less detailed metadata descriptions, or less resources with more metadata detail. Full descriptions cost more to create and thus, how comprehensive the data is must be weighed against the cost (Hider, 2018, p. 95);
Brief descriptions aid FRBR discovering (but not selecting) (Hider, 2018, p.95).
Accuracy:
Metadata must be accurate and consistently evaluated and corrected, because small errors can result in a failure for the user to find, identify, select, obtain or explore the information (Hider, 2018, p.95).
Clarity
Metadata descriptive words are chosen carefully to enable clarity. Without clarity, accuracy is moot – including language choice, jargon, abbreviations, codes, homonyms, or even changes in word popularity / common use (e.g. what is commonly called a title = ‘title proper’ to cataloguers; subtitle = ‘other title information’; or a title in a different language = ‘parallel title’) (Hider, 2018, p.96); Here is a screen shot of some common abbreviations used:
Rowe, 2019, Module 3.2 Screen shot of abbreviations
Quality metadata also has clarity, in that it is succinct – brief indexes may improve search results as the fewer the terms, the fewer irrelevant search results occur (Hider, 2018, p.97).
Consistency:
Being consistent, using the same elements and values aids FRBR retrieval across multiple systems (aka interoperability) (Hider, 2018, p.97);
Consistency (in descriptions, lengths, structures and terminologies used in indexes) aids in all FRBR functions (find, identify, select, obtain or explore) (Hider, 2018, p.97);
Consistency of understanding between the cataloguer/indexer and the user / searcher is also important and this is achieved by standardisation (Hider, 2018, p.98);
Vocabulary control, an aspect of consistency, is where the cataloguer/indexer use the same, standardised language, utilising cross referencing tools such as ‘see also’ (Hider, 2018, p.99-100);
Authority control, also an aspect of consistency, is where the names of people, nicknames/pseudonyms/varied bibliographic identities/people with the same name, organisations or corporate bodies, or titles and series are standardised in a list (such as this list by the Library of Congress or this list of standards by the National Libraries of Australia) or written to include birth years (Hider, 2018, p.101-102);
Evaluation systems such as quality control (QC) processes, audits, quality assurance (QA) processes including quality measures and benchmarks, checklists or scorecards ensure metadata consistency based on user needs (Hider, 2018, p.104).
A range of standards for a range of environments
“A range of standards have been developed for all aspects of metadata, including its values, elements, format and transmission” (Hider, 2018, p.123).
These metadata standards relate to ‘key information domains’, such as:
Book publishing – Copy editors refer to ‘style manuals’ such as: the Chicago Manual of Style, Publication Manual of the American Psychological Association, MLA Handbook, and AMA Manual of Style; Electronic text publishers adhere to online standards such as the Text Encoding Initiative (TEI) or the Online Information Exchange (ONIX) (Hider, 2018, p.163);
Research – data repositories such as: UK Data Archives, Australian National Data Service (ANDS), Content Standard for Digital Geospatial Metadata (CSDGM), Australia and New Zealand Spatial Information Council (ANZLIC) Metadata Profile, Darwin Core (DwC), earth sciences Directory Interchange Format, space science Space Physics Archive Search and Extract (SPACE) Data Model, and the social science Data Documentation Initiative (DDI) (Hider, 2018, p.165-166).
Education – The Institute of Electrical and Electronics Engineers (IEEE) Learning Object Metadata standard (IEEE-LOM), the Gateway to Educational Materials schema (in USA), Education Network Australia (EdNA) schema, and, more recently, the Australia and New Zealand Learning Object Metadata standard (ANZ-LOM) by Education Services Australia (Hider, 2018, p. 167).
Web publishing – Hypertext Markup Language (HTML), Extensible Markup Language (XML) [with namespaces including Universal Resource Identifier (URI/URL)], and Resource Description Framework (RDF) as specified by the World Wide Web Consortium (W3C); (Rowe, 2019, Module 3.3; Hider, 2018, p.124-127);
Digital Libraries – Dublin Core (DC), Metadata Object Description Schema (MODS) and Metadata Authority Description Schema (MADS), Metadata Encoding and Transmission Standard (METS), Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) and OpenURL (providing access to journal content within subscribed databases); (Rowe, 2018, Module 3.3; Hider, 2018, p. 150, 153-154);
Archives – General International Standard Archival Description (ISAD(G) similar to ISBD below) and Encoded Archival Description (EAD); (Rowe, 2018, Module 3.3; Hider, 2018, p. 155-156, 158);
Museums – Standard Procedures for Collections Recording Used in Museums (SPECTRUM), International Committee for Documentation (CIDOC) International Guidelines for Museum Object Information: the CIDOC information categories (1995) and CRM; (Rowe, 2018, Module 3.3; Hider, 2018, p. 160-161);
Libraries – The Statement of International Cataloguing Principles (Published by the International Federation of Library Associations (IFLA) in 2009 updated in 2016), Anglo American Cataloguing Rules (AACR/AACR2), International Standard Bibliographic Description (ISBD), Machine Readable Cataloguing (MARC/MARC21) (a format for the automatic electronic sharing of library catalogue data – including the description, main entry/entries, subject heading(s) and Dewey Decimal ‘call number’ – that may be updated to the Bibliographic Framework Transition Initiative (BIBFRAME) in the future); Z39.50 (client server information retrieval protocol for large searches); and finally, Resource Description Access (RDA) which is based on the Functional Requirements for Bibliographic Records (FRBR) and Functional Requirements for Authority Data (FRAD), (Rowe, 2019, Module 3.3; Hider, 2018, p.132-133, 136, 142-143, 147, 149; Furrie, 2009).
Registries of standards – To keep track of all of the standards as they grow and change over time and to select the appropriate standard or crosswalks between various standards for their tasks, metadata specialists use registries of standards such as: “the Open Metadata Registry, the Dublin Core Metadata Registry, the Basel Register of Thesauri, Ontologies and Classifications (BARTOC) and Schema.org, the last of which encourages individuals from across domains to join its community of schema developers” (Hider, 2018, p.168).
What is RDA and the RDA toolkit?
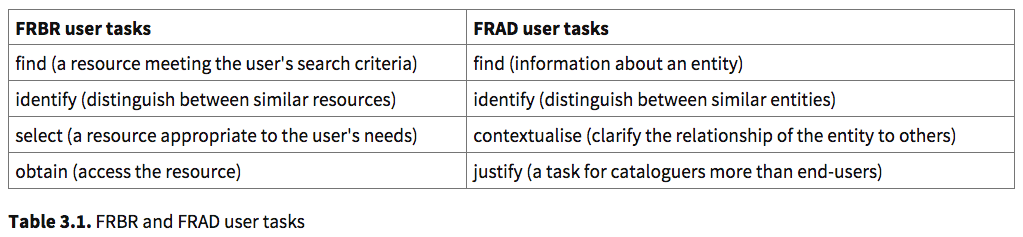
RDA (the main current standard for descriptive cataloguing) was built on the foundational basis of how effective catalogues operate, namely, FRBR & FRAD and is conceptualised by certain things which have inter-relationships to other things, thereby ensuring that users can search for and access information successfully (Hider, 2018, p.136; Oliver, 2010, p.14-15).
Find: “…(T)o bring together information about one or more resources of interest by searching on any relevant criteria” IFLA, 2017, p. 15 in Hider, 2018, p.29; Oliver, 2010, p.15) “The most precise attribute for this purpose is an identifier, which frequently takes the form of a number, uniquely assigned to a particular resource. Another attribute that often serves to identify a resource is its name. This can be more descriptive than an identifier, but may not be totally unique. Nevertheless, it often does the job and is more likely to be remembered than an ‘artificial’ identifier” (Hider, 2018, p.31). “A prime example of a systematic identifier at this level is the ISBN (ISSN, ISTC or ISAN)” (Hider, 2018, p.34);
Identify: “(To identify is) to clearly understand the nature of resources found and to distinguish between similar resources” (IFLA, 2017, p. 15 in Hider, 2018, p.29; Oliver, 2010, p.15); “A manifestation of a work, such as a particular printing of a book, is also unlikely to be named, except in very generic terms, such as ‘third printing’ or ‘2003 release’. This sort of metadata may be used in the identification or selection process, but it is seldom used to find the resource. A user may choose between a PC and a Mac version, or prefer an earlier printing if they are a literary scholar” (Hider, 2018, p.31); “To this end, users need sufficient and accurate description” (Hider, 2018, p.34); “Similarly, if a particular manifestation is required and there is no systematic identifier such as an ISBN to check, the user will typically start by identifying the work and then look at attributes pertaining to the carrier, especially publication and format. At the item level, users may consider attributes such as provenance, i.e. the item’s custodial history, to identify, for example, a piece of art or an archival file” (Hider, 2018, p.35).
Select: “(To select is) to determine the suitability of the resources found, and to be enabled to either accept or reject specific resources” (IFLA, 2017, p. 15 in Hider, 2018, p.29; Oliver, 2010, p.15); “…the selection process essentially occurs inside the user’s head” (Hider, 2018, p.39); “On reading the resource descriptions, the user may be influenced by other elements that they then realise are relevant to the selection process” (Hider, 2018, p.36); “In the field of information retrieval, the attributes used to select resources are referred to as relevance criteria” (Hider, 2018, p.36); “The kind of resource people want, when they do not have a specific resource in mind, often relates to the subject of its content” (Hider, 2018, p.36); “Other aspects of a resource’s content may also be of interest to selectors. For example, users may well be interested in its quality, in which case comments, reviews and ratings can be helpful. The currency of content may also be a factor to consider, so the user may look for a creation date or copyright year, for example. Likewise, the amount of content (e.g. the number of words) may have a bearing. The form of a work could also be relevant. It may be ‘about’ Japan, but it may be a map, website or film documentary. It turns out, then, that information content can be described in many different, and sometimes unanticipated, ways” (Hider, 2018, p.36).
Obtain: “To access the content of the resource” (IFLA, 2017, p. 15 in Hider, 2018, p.29); “To acquire or obtain access to the entity described (ie. to acquire an entity through purchase, loan, etc., or to access an entity electronically through an online connection to a remote computer” (Oliver, 2010, p.15). “In today’s online world, users often need very little by way of metadata in order to obtain, or gain access to, an information resource – just a label on a hyperlink…information about how to obtain it…is the resource’s location” (Hider, 2018, p.39).
Explore: “To discover resources using the relationships between them and thus place the resources in a context” (IFLA, 2017, p. 15 in Hider, 2018, p.29); “In today’s networked world, these linkages are underpinned by the hyperlink mechanism, whereby the linked record is only a mouse-click away. In the analogue world, one might have to look up a cross-reference” (Hider, 2018, p.39); “(T)his process allows the user…to get a feel for a network of resources through their surrogate records. … Relationships between resources, their commonalities and their differences are the heart of what organisation is about (sic)” (Hider, 2018, p.40).
FRBR vs FRAD (Rowe, 2019, Module 3.3) See also, Oliver, 2010, p. 16.
Creating bibliographic records for selected information resource using RDA
SCIS have excellent information resource standards for cataloguing and data entry, based on FRBR/FRAD/RDA. Rowe (2019, module 3.5) has shared an amazing video to help navigate the RDA toolkit, as well as a table to help create a bibliographic record using RDA, which I’ve uploaded to GoogleSheets, including notes from Rowe (2019, Module 3.5). Furthermore, Rowe (2019) writes:
“When using the RDA Toolkit you should note the following…Instructions within RDA move from the general to the specific. … The appendices of RDA contain supplementary information including, among other things, guidelines for capitalisation and abbreviations and symbols, and in Appendices I through to M you will find the controlled lists of relationship designators. There is a glossary which is particularly useful if you are unfamiliar with terminology. RDA also contains a Tools Tab where you will find mappings from RDA to MARC and MARC to RDA; workflows contributed by RDA users; an index to the RDA Toolkit; and examples of records encoded in MARC format. The Resources Tab includes the full text of AACR2; and policy statements from agencies including the National Library of Australia and the Library of Congress-Program for Cooperative Cataloging, as well as a link to the MARC Standards” (Rowe, 2019, Module 3.5).
Screen Shot of the RDA Toolkit taken by Christy Roe August 2020
Welsh, A., & Batley, S. (2012). Bibliographic elements. In Practical cataloguing: AACR, RDA and MARC 21 (pp.17-48). London: Facet. Available from eBook Library.
Resources must be NAVIGATED, Discovered, Identified, Selected, Obtained
In order for an information seeker or library user to effectively navigate a library collection, they must be taught how to use the organisational tools for that setting, such as: catalogues, databases (periodical / citation / image / etc), bibliographies, subject guides / gateways, directories or search engines, to name a few (Rowe, 2019, Module 2.1) this includes staff, parents, students, the general public, etc.
“The arrangement of resources by Dewey Decimal Classification, alphabetical order and, on occasion, by other attributes such as type of material, level of difficulty, and genre, along with the use of indexes and databases, such as the library catalogue, are key tools of information retrieval used in school libraries” (Rowe, 2019, Module 2.1).
Tools and systems
To truely be considered an effective information retrieval organisational system, systems must not simply be based on content (i.e. Google or #tags) but must also be based on the elements of metadata – such as is found in library catalogues and archival finding aids, and must be 1. arranged, 2. labelled and/or 3. indexed (Hider, 2018, p.43).
Arrangements: by author or by genre? Either way, a standardised protocol (e.g. The Dewey Decimal Classification or DDC) is the first step (Hider, 2018, p.44).
Labels are also key, either individual resource labels or labelled in groups, using either words or numerical notations for words/subject matter (Hider, 2018, p.44-45).
Indexing, is a basic information organisational tool for collections or single resources which uses compact, descriptive, efficient and effective metadata which, in turn, allows multiple access points (e.g. title, author, institution, series, numerical identifiers, etc) for end-users/information seekers (and the more points of access = the greater the chance of success) (Hider, 2018, p.46). Indexes can be closed (once-off & static), open (growing & flexible), card (outdated in today’s libraries), or computer ‘bibliographic’ databases (e.g. SCIS) (Hider, 2018, p.47-49). Indexes form the basis for information retrieval organisation systems such as catalogues, bibliographic databases (e.g. library catalogue) / citation databases, museum registers, archival finding aids, content management systems and search engines (Hider, 2018, p.46; 50).
Library catalogues
Around 1970’s-1980’s, OPAC (online public access catalogue) was the first database to take over paper card catalogues, and was a huge international human data entry task using MARC (machine readable cataloging in a standard format) (Hider, 2018, p.52). OPAC/MARC allowed more access points and has continually grown over time to include things like Boolean searching, truncation, and multiple &/or remote access (Hider, 2018, p.52-53). However, it is important to note that more work is needed to make library catalogues designed in the MARC format competitive with Google:
“Perhaps an even greater issue, however, is the scope of library catalogues. Nowadays they represent only a certain proportion of information resources provided by the library, and only a tiny proportion of resources available in the online environment as a whole. As Ruschoff (2010, 62) argues, ‘more lipstick on our catalogs is not going to make our OPACs the search engine of tomorrow’. Since it is clearly impossible for libraries to catalogue all the useful resources now available on the internet, the way forward appears to be for libraries to ensure that their metadata is out there in the wider online environment: if they can’t beat the likes of Google, they need to join them” (Hider, 2018, p.57).
Sharing library catalogues / metadata
Metadata that has been created using agreed standardised protocols such as MARC / RDA, as well as containing the agreed set of elements, it can be used in different information retrieval systems at different institutions, creating ‘bibliographic networks’ and even ‘bibliographic utilities,’ and ‘union catalogues’ offering the benefit of it only having to be created once, saving a great deal of time and expense (Hider, 2018, p111-112; 115).
One such ‘bibliographic utility’ is the SCIS catalogue. Chadwick (2015, p.12) points out that by purchasing their catalogue, schools can save hundreds of data entry hours (and money paying employees) and can obtain a more narrow, school-focussed catalogue (as opposed to the more broad catalogues available from places like the National Library).
However, it is one thing to offer a catalogue to share, and another for that catalogue to be able to transmit over to a setting’s computer system. In order to ‘transmit,’ a setting must have particular protocols, such as Z39.50. “Z39.50 is an ‘application layer network protocol’ covered by the ANSI/NISO Z39.50 and ISO 23950 standards and maintained by the Library of Congress. Application layer protocols provide computer programs with a common language when sharing data across networks. Some well-known application layer protocols include Hypertext Transfer Protocol (HTTP) and File Transfer Protocol (FTP). Z39.50 allows a system – usually a LMS – to search and retrieve information from bibliographic databases across the world” (Chadwick, 2015b, paragraph 2).
As well as sharing amongst library databases, various databases and even repositories, archives and museums now share their catalogues with search engines and social media applications, improving their catalogue accessibility (Hider, 2018, p.116). “Libraries, museums, archives, universities and publishers are all coming to realise that their websites are not necessarily the first port of call for information seekers. The reality is that, far more often, search engines such as Google are” (Hider, 2018, p.117).
Which brings to the fore the issue of ‘interoperability’ or the ability of metadata created using MARC’s ability to work in a variety of systems, where, if the metadata is not using the same standardised protocols as MARC, it must be converted into a transmittable format using ‘maps’ and ‘crosswalks’ such as ‘Dublin Core’ or DC (Hider, 2018, p.117-118) and Michael Day has provided a great list of maps and crosswalks for a variety of system conversions.
Library databases as a school hub / Learning commons
Combes (2012, p.6-7) makes a great point: schools should be fully utilising their library catalogue / database / information management system to include all resources, even those not housed in the library, including: “class sets; ‘old’ technology resources such as video recorders and TVs; and ‘newer’ technology such as laptops, e-book readers, interactive whiteboards, USB sticks and digital cameras as catalogued items.”
Furthermore, she also makes the point that the catalogues / databases / information management systems should be exemplary teaching models of web design, utilising the most efficient layout, colours, disability access, displays, navigation, interconnectivity and access points (Coombes, 2012, p.7).
Federated search systems
Hider (2018, p.58-59) pushes this concept of libraries as information hubs a bit further through the use of federated search systems, creating ‘service convergence.’ Federated search systems allow users to search multiple databases simultaneously – much like the CSU library ‘Primo’ or the National Library of Australia’s ‘Trove’ function. However, these rely on 1. access globally (rather than simply to those who pay the registration fee) 2. the various databases to all speak the same ‘language’ in terms of language, syntax and semantics, and 3. the various databases must also use similar ‘standardised’ cataloguing protocols as those used by the library setting(s) (Hider, 2018, p.58-59).
Content management and repository systems: Intranet
The large amounts of digital content organisations are producing is managed via different content management systems, intranet and software or ‘institutional repositories’ of various natures and sizes, which have been amalgamated by staff or peer groups They vary enormously in nature and size and may be new or ‘old’ resources being converted digitally (Hider, 2018, p.64-65). These institutional repositories may have textual content (e.g. academic papers, theses, old newspapers, recipes), audiovisual content (images, videos, sound recordings) or multimedia content (e.g. websites). (Hider, 2018, p.64-65).
Combes, B. (2012). Practical curriculum opportunities and the library catalogue. Connections, 2012(82), 5-7. (On the SCIS home page, click on ‘Connections’ Issue 82, Term 3 2012 & download issue).
Hider, P. (2018). Information resource description: Creating and managing metadata (2nd ed.). London: Facet.
Witten, I. H., Bainbridge, D., & Nichols, D. M. (2010). How to build a digital library (2nd ed.). Burlington, MA: Morgan Kaufmann. Available from CSU eBooks. (‘The scope of digital libraries’, p. 6-9 and ‘Metadata: Elements of organisation’ p. 285-286)